【一】参数化
录制脚本中有登录操作,需要输入用户名和密码,假如系统不允许相同的用户名和密码同时登录,或者想更好的模拟多个用户来登录系统。
这个时候就需要对用户名和密码进行参数化,使每个虚拟用户都使用不同的用户名和密码进行访问。
1、准备脚本,测试数据
1)、写一个脚本(可以用badboy工具录制),在jmeter中打开,找到有用户名和密码的页面。如下:
2、我们需要“参数化”的数据,用记事本写了五个用户名和密码,保存为.dat格式的文件,编码问题在使用CSV Data Set Config参数化时要求的比较严格,记事本另存为修改编码UTF-8. 注意用户名和密码是一一对应的,中间用户逗号(,)隔开。
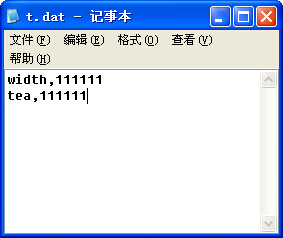
我将这个文件放在了我的( C:\JmeterWorkSpace\t.dat )路径下。
2、参数化
这里介绍两种参数化的方式:函数助手,CSV Data Set Config。
1)、借助函数助手的方式
a、点击菜单栏“选项”---->函数助手对话框,看下图: CSV文件列号是从0开始的,第一列0、第二列1、第三列2、依次类推。。
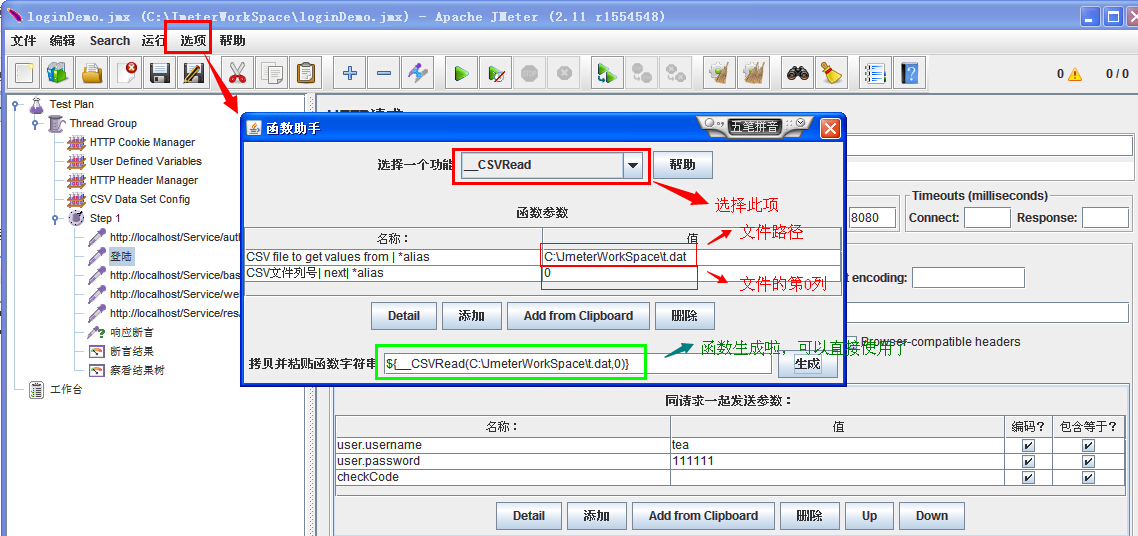
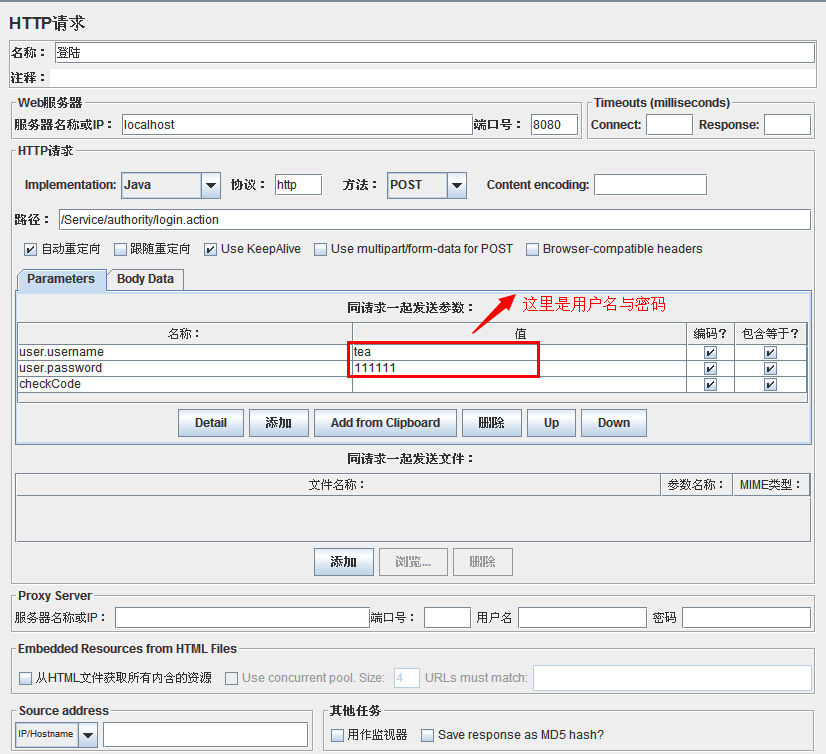
b、复制生成的参数化函数,打开登陆请求页面,在右则的参数化中找到我们要参数化的字段,这里对用户名和密码做参数化,第一列是用户名,列号为0;第二列是密码,列号为1;修改函数中对应的参数化字段列号就可以啦。
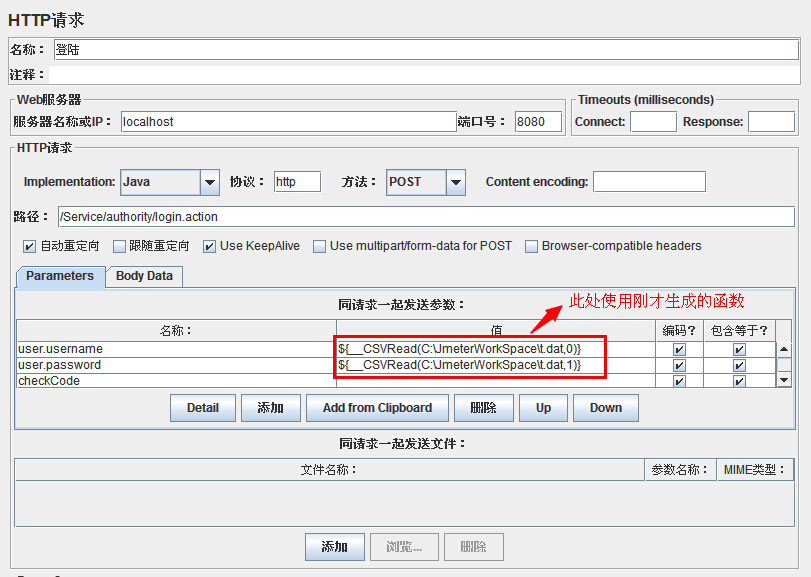
现在参数化设置完成,在脚本的时候,会调用我们C:\JmeterWorkSpace盘下面的t.dat文件,第一列是用户,第二列是密码。
2)、借助jmeter中的配置元件(CSV Data Set Config)
a、选中线程组,点击右键,添加-配置元件-CSV Data Set Config
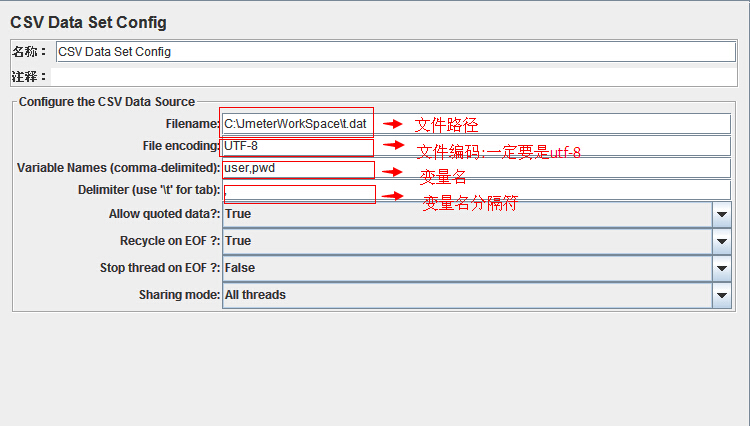
说明:
Filename --- 参数项文件
File Encoding --- 文件的编码,设置为UTF-8Vaiable Names --- 文件中各列所表示的参数项;各参数项之间利用逗号分隔;参数项的名称应该与HTTP Request中的参数项一致。Delimiter --- 如文件中使用的是逗号分隔,则填写逗号;如使用的是TAB,则填写\t;(如果此文本文件为CSV格式的,默认用英文逗号分隔)Recycle on EOF? --- True=当读取文件到结尾时,再重头读取文件
False=当读取文件到结尾时,停止读取文件Stop thread on EOF? --- 当Recycle on EOF为False时,当读取文件到结尾时,停止进程,当Recycle on EOF为True时,此项无意义
备注说明:这里我用通俗的语言大概讲一下Recycle on EOF与Stop thread on EOF结果的关联
Recycle on EOF :到了文件尾处,是否循环读取参数,选项:true和false
Stop thread on EOF:到了文件尾处,是否停止线程,选项:true和false
当Recycle on EOF 选择true时,Stop thread on EOF选择true和false无任何意义,通俗的讲,在前面控制了不停的循环读取,后面再来让stop或run没有任何意义
当Recycle on EOF 选择flase时,Stop thread on EOF选择true,线程4个,参数3个,那么只会请求3次
当Recycle on EOF 选择flase时,Stop thread on EOF选择flase,线程4个,参数3个,那么会请求4次,但第4次没有参数可取,不让循环,所以第4次请求错误
b、使用刚才定义好的变量
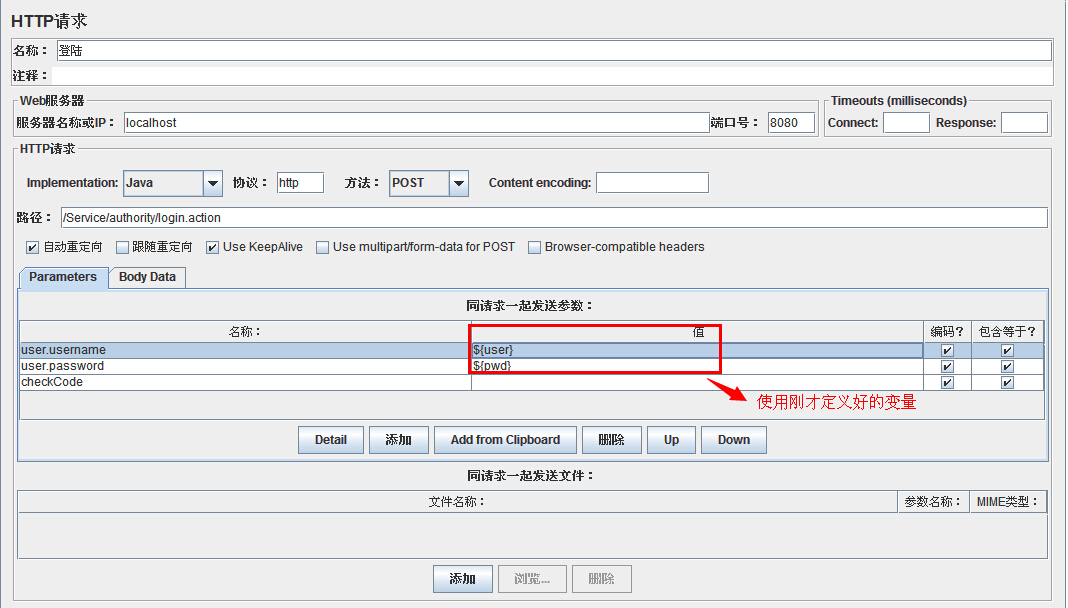
至此,两种参数化的方法就介绍完了。
需要说明一下:函数助手方法要比CSV控件方法参数化功能要弱,推荐使用CSV控件方法。
再看看与loadrunner参数化不一样的:
1、 jmeter参数文件的第一行没有列名称
2、 这里要注意的是参数文件的编码,可以使用记事本另存为就可以修改该编码(编码问题在使用CSV Data Set Config参数化时要求的比较严格)
3、 Jmeter的参数化设置没有LoadRunner做的出色,它是依赖于线程设置的(只有CSV Data Set Config参数化方法才有)
【二】User Parameters(用户参数)
1、User Defined Variables
a 添加方法:选择“线程组”,右键点击添加-Config Element-User Defined Variables,在这个控件中,定义你所需要的参数,如

b、使用方法:在对应的需要使用参数的位置,使用${host}替代。
c、应用场景:当测试环境变化时,我们只需要修改一处的IP就可以让脚本马上应用于另外一个环境的测试,而不需要逐个脚本进行修改。
2、User Parameters
a、添加方法:选择“线程组”,右键点击添加-Pre Processors-User Parameters,在这个控件中,定义你所需要的参数,如
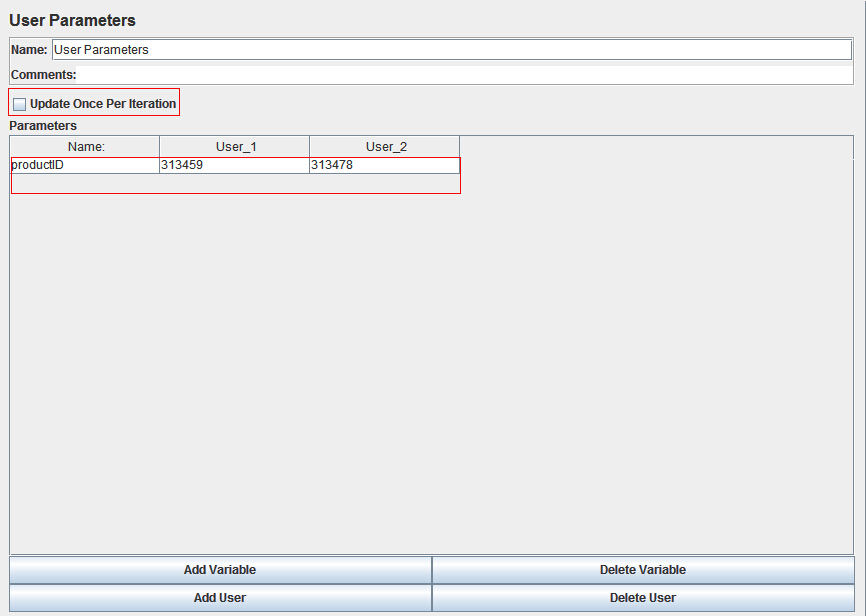
3、参数解释:
Update Once Per Iteration:控制参数取值的变化规则,如果选中该选项,则参数的值在每个迭代中保持不变,在新的迭代开始时取下一个可用值; 如果取消取中该选项,则参数的值在每个其作用域内的Sampler发出请求时取下一个可用值。
4、使用方法:在对应的需要使用参数的位置,使用${productID}替代。
三、小结
1、User Defined Variables中定义的所有参数的值在Test Plan的执行过程中不能发生取值的改变,因些一般仅将Test Plan中不需要随迭代发生改变的参数(只取一次值的参数)设置在此处。例如,被测应用的host和port值。
2、如果参数的取值范围很小,使用User Parameters比较合适。
3、如果参数的取值范围很大,建议使用CSV Data Set Config的方法,该方法具有更大的灵活性。
【三】正则提取器
(正则表达式提取器是Jmeter关联中的一种)使用场景:
有两个HTTP请求,请求A的返回数据中有一个字段“ABCD”的值,该字段要作为请求B的入参。
1、添加方式
请求A上右键-->后置处理器->正则表达式提取器
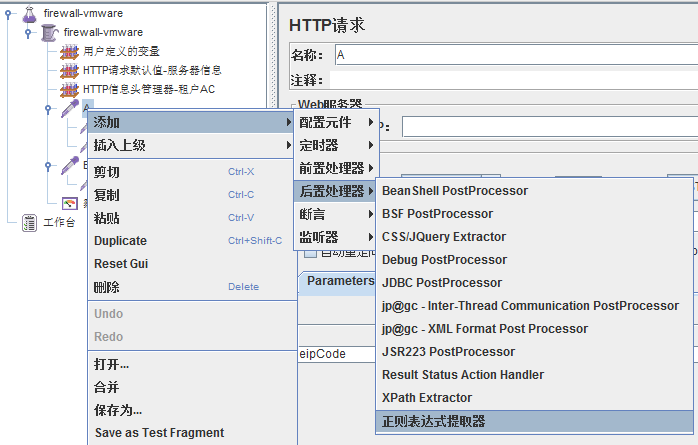
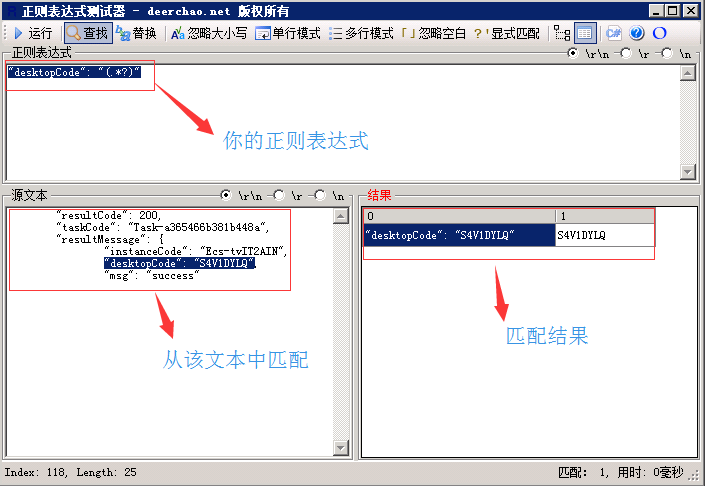
2、提取A请求中的taskCode对应的值

为了获取到上图中圈起来的这个值,要配置正则表达式提取器:

说明:
(1)引用名称:下一个请求要引用的参数名称,如填写Atask,则可用${Atask}引用它。
(2)正则表达式:
():括起来的部分就是要提取的。
(3)模板:用$$引用起来,如果在正则表达式中有多个正则表达式,则可以是$2$$3$等等,表示解析到的第几个值给title。如:$1$表示解析到的第1个值
(4)匹配数字:0代表随机取值,1代表全部取值,通常情况下填0
(5)缺省值:如果参数没有取得到值,那默认给一个值让它取,我填的Error。
3、获取到的值传入B请求
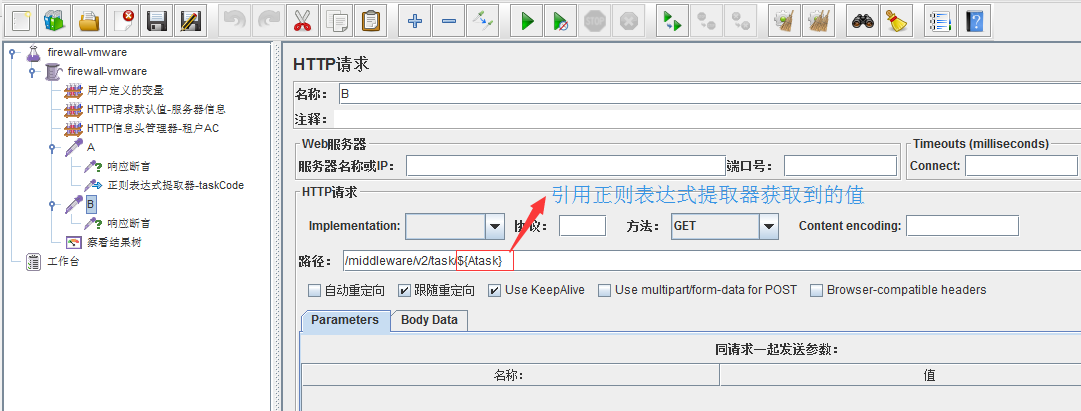
看一下请求B是否如预期的一样传入Atask这个值

引用成功~~
记录一个好用的测试正则表达式的工具:
工具名称:RegexTester
使用方法: